Introduction
Amoro is a Lakehouse management system built on open data lake formats. Working with compute engines including Flink, Spark, and Trino, Amoro brings pluggable and self-managed features for Lakehouse to provide out-of-the-box data warehouse experience, and helps data platforms or products easily build infra-decoupled, stream-and-batch-fused and lake-native architecture.
Architecture
The architecture of Amoro is as follows:
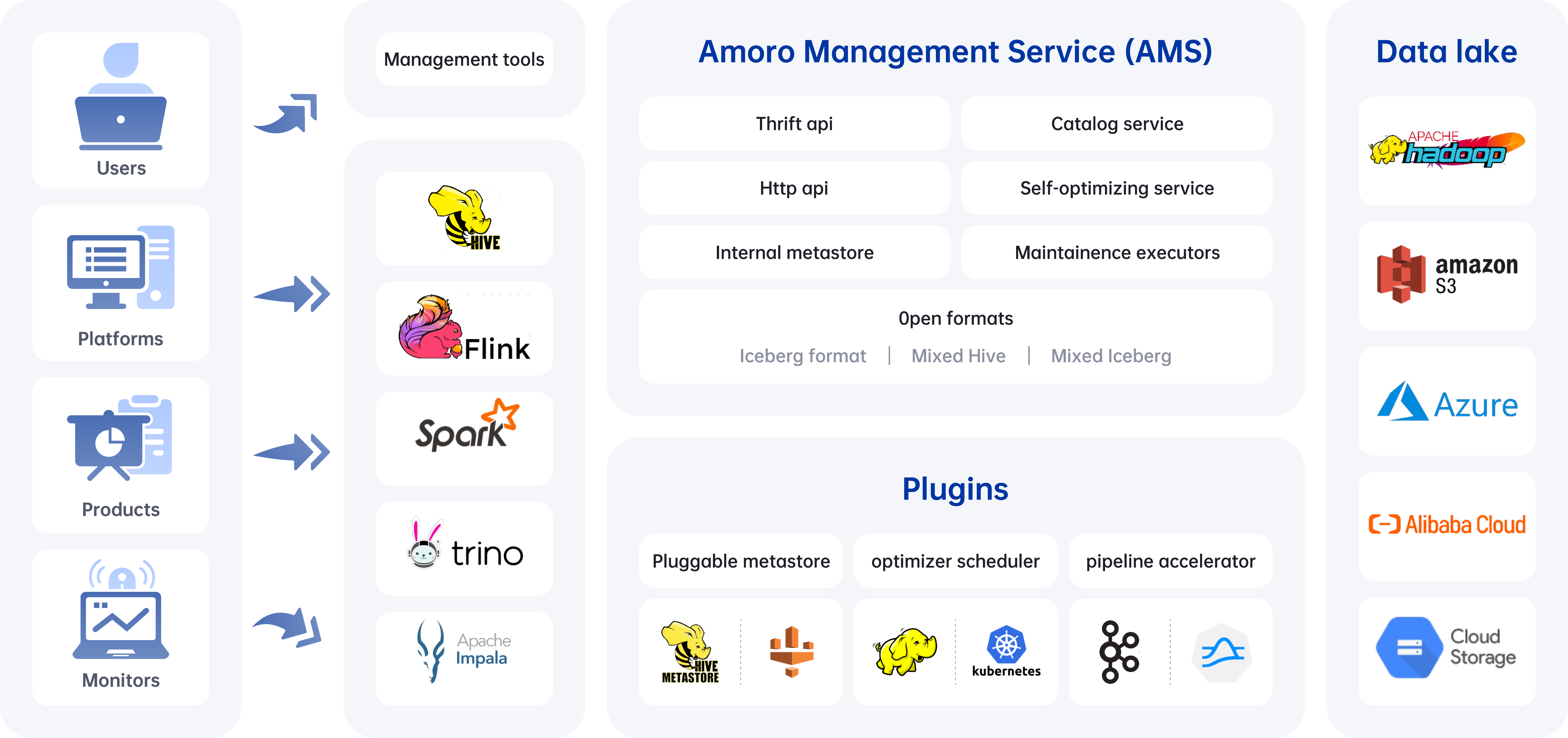
The core components of Amoro include:
- AMS: Amoro Management Service provides Lakehouse management features, like self-optimizing, data expiration, etc. It also provides a unified catalog service for all compute engines, which can also be combined with existing metadata services.
- Plugins: Amoro provides a wide selection of external plugins to meet different scenarios.
- Optimizers: The self-optimizing execution engine plugin asynchronously performs merging, sorting, deduplication, layout optimization, and other operations on all type table format tables.
- Terminal: SQL command-line tools, provide various implementations like local Spark and Kyuubi.
- LogStore: Provide millisecond to second level SLAs for real-time data processing based on message queues like Kafka and Pulsar.
Supported table formats
Amoro can manage tables of different table formats, similar to how MySQL/ClickHouse can choose different storage engines. Amoro meets diverse user needs by using different table formats. Currently, Amoro supports three table formats:
- Iceberg format: means using the native table format of the Apache Iceberg, which has all the features and characteristics of Iceberg.
- Mixed-Iceberg format: built on top of Iceberg format, which can accelerate data processing using LogStore and provides more efficient query performance and streaming read capability in CDC scenarios.
- Mixed-Hive format: has the same features as the Mixed-Iceberg tables but is compatible with a Hive table. Support upgrading Hive tables to Mixed-Hive tables, and allow Hive’s native read and write methods after upgrading.
Supported engines
Iceberg format
Iceberg format tables use the engine integration method provided by the Iceberg community. For details, please refer to: Iceberg Docs.
Paimon format
Paimon format tables use the engine integration method provided by the Paimon community. For details, please refer to: Paimon Docs.
Mixed format
Amoro support multiple processing engines for Mixed format as below:
| Processing Engine | Version | Batch Read | Batch Write | Batch Overwrite | Streaming Read | Streaming Write | Create Table | Alter Table |
|---|---|---|---|---|---|---|---|---|
| Flink | 1.15.x, 1.16.x and 1.17.x | ✔ | ✔ | ✖ | ✔ | ✔ | ✔ | ✖ |
| Spark | 3.1, 3.2, 3.3 | ✔ | ✔ | ✔ | ✖ | ✖ | ✔ | ✔ |
| Hive | 2.x, 3.x | ✔ | ✖ | ✔ | ✖ | ✖ | ✖ | ✔ |
| Trino | 406 | ✔ | ✖ | ✔ | ✖ | ✖ | ✖ | ✔ |
User cases
Self-managed streaming Lakehouse
Amoro makes it easier for users to handle the challenges of writing to a real-time data lake, such as ingesting append-only event logs or CDC data from databases. In these scenarios, the rapid increase of fragment and redundant files cannot be ignored. To address this issue, Amoro provides a pluggable streaming data self-optimizing mechanism that automatically compacts fragment files and removes expired data, ensuring high-quality table queries while reducing system costs.
Stream-and-batch-fused data pipeline
Whether in the AI or BI business field , the requirement for real-time analysis is becoming increasingly high. The traditional approach of using one streaming job to complete all data processing from the source to the end is no longer applicable. There is an increasing demand for layered construction of streaming data pipeline, and the traditional layered construction approach based on message queues can cause a inconsistency problem between the streaming and batch data processing. Building a unified stream-and-batch-fused pipeline based on new data lake formats is the future direction for solving these problems. Amoro fully leverages the characteristics of the new data lake table formats about unified streaming and batch processing, not only ensuring the quality of data in the streaming pileline but also enhancing critical features such as incremental reading for CDC data and streaming dimension table association, helping users to build a stream-and-batch-fused data pipeline.
Cloud-native Lakehouse
Currently, most data platforms and products are tightly coupled with their underlying infrastructure(such as the storage layer). The migration of infrastructure, such as switching to cloud-native OSS, may require extensive adaptation efforts or even be impossible. However, Amoro provides an infra-decoupled, lake-native architecture built on top of the infrastructure. This allows products based on Amoro to interact with the underlying infrastructure through a unified interface (Amoro Catalog service), protecting upper-layer products from the impact of infrastructure switch.