Managing Optimizers
The optimizer is the execution unit for performing self-optimizing tasks on a table. To isolate optimizing tasks on different tables and support the deployment of optimizers in different environments, Amoro has proposed the concepts of optimizer containers and optimizer groups:
- Optimizer container: Encapsulate the deployment method of optimizers, there are three implementations for now:
flink containerbased on Flink streaming job,local containerbased on Java Application, andexternal containerbased on manually started by users. - Optimizer group: A collection of optimizers, where each table must select an optimizer group to perform optimizing tasks on it. Tables under the same optimizer group contribute resources to each other, and tables under different optimizer groups can be isolated in terms of optimizer resources.
- Optimizer: The specific unit that performs optimizing tasks, usually with multiple concurrent units.
Optimizer container
Before using self-optimizing, you need to configure the container information in the configuration file. Optimizer container represents a specific set of runtime environment configuration, and the scheduling scheme of optimizer in that runtime environment. The container includes three types: flink, local, and external.
Local container
Local container is a way to start Optimizer by local process and supports multi-threaded execution of Optimizer tasks. It is recommended to be used only in demo or local deployment scenarios. If the environment variable for jdk is not configured, the user can configure java_home to point to the jdk root directory. If already configured, this configuration item can be ignored.
containers:
- name: localContainer
container-impl: com.netease.arctic.server.manager.LocalOptimizerContainer
properties:
export.JAVA_HOME: "/opt/java" # JDK environment
Flink container
Flink container is a way to start Optimizer through Flink jobs. With Flink, you can easily deploy Optimizer
on yarn clusters or kubernetes clusters to support large-scale data scenarios. To use flink container,
you need to add a new container configuration. with container-impl as com.netease.arctic.server.manager.FlinkOptimizerContainer
FlinkOptimizerContainer support the following properties:
| Property Name | Required | Default Value | Description |
|---|---|---|---|
| flink-home | true | N/A | Flink installation location |
| target | true | yarn-per-job | flink job deployed target, available values yarn-per-job, yarn-application, kubernetes-application |
| job-uri | false | N/A | The jar uri of flink optimizer job. This is required if target is application mode. |
| ams-optimizing-uri | false | N/A | uri of AMS thrift self-optimizing endpoint. This could be used if the ams.server-expose-host is not available |
| export.<key> | false | N/A | environment variables will be exported during job submit |
| export.JAVA_HOME | false | N/A | Java runtime location |
| export.HADOOP_CONF_DIR | false | N/A | Direction which holds the configuration files for the hadoop cluster (including hdfs-site.xml, core-site.xml, yarn-site.xml ). If the hadoop cluster has kerberos authentication enabled, you need to prepare an additional krb5.conf and a keytab file for the user to submit tasks |
| export.JVM_ARGS | false | N/A | you can configure flink to run additional configuration parameters, here is an example of configuring krb5.conf, specify the address of krb5.conf to be used by Flink when committing via -Djava.security.krb5.conf=/opt/krb5.conf |
| export.HADOOP_USER_NAME | false | N/A | the username used to submit tasks to yarn, used for simple authentication |
| export.FLINK_CONF_DIR | false | N/A | the directory where flink_conf.yaml is located |
| flink-conf.<key> | false | N/A | Flink Configuration Options will be passed to cli by -Dkey=value, |
To better utilize the resources of Flink Optimizer, it is recommended to add the following configuration to the Flink Optimizer Group:
- Set
flink-conf.taskmanager.memory.managed.sizeto32mbas Flink optimizer does not have any computation logic, it does not need to occupy managed memory. - Set
flink-conf.taskmanager.memory.netwrok.maxto32mbas there is no need for communication between operators in Flink Optimizer. - Set
flink-conf.taskmanager.memory.netwrok.ninto32mbas there is no need for communication between operators in Flink Optimizer.
An example for yarn-per-job mode:
containers:
- name: flinkContainer
container-impl: com.netease.arctic.server.manager.FlinkOptimizerContainer
properties:
flink-home: /opt/flink/ #flink install home
export.HADOOP_CONF_DIR: /etc/hadoop/conf/ #hadoop config dir
export.HADOOP_USER_NAME: hadoop #hadoop user submit on yarn
export.JVM_ARGS: -Djava.security.krb5.conf=/opt/krb5.conf #flink launch jvm args, like kerberos config when ues kerberos
export.FLINK_CONF_DIR: /etc/hadoop/conf/ #flink config dir
An example for kubernetes-application mode:
containers:
- name: flinkContainer
container-impl: com.netease.arctic.server.manager.FlinkOptimizerContainer
properties:
flink-home: /opt/flink/ # Flink install home
target: kubernetes-application # Flink run as native kubernetes
job-uri: "local:///opt/flink/usrlib/optimizer-job.jar" # Optimizer job main jar for kubernetes application
ams-optimizing-uri: thrift://ams.amoro.service.local:1261 # AMS optimizing uri
export.FLINK_CONF_DIR: /opt/flink/conf/ # Flink config dir
flink-conf.kubernetes.container.image: "arctic163/optimizer-flink:{version}" # Optimizer image ref
flink-conf.kubernetes.service-account: flink # Service account that is used within kubernetes cluster.
External container
External container refers to the way in which the user manually starts the optimizer. The system has a built-in external container called external, so you don’t need to configure it manually.
Optimizer group
Optimizer group (optimizer resource group) is a concept introduced to divide Optimizer resources. An Optimizer Group can contain several optimizers with the same container implementation to facilitate the expansion and contraction of the resource group.
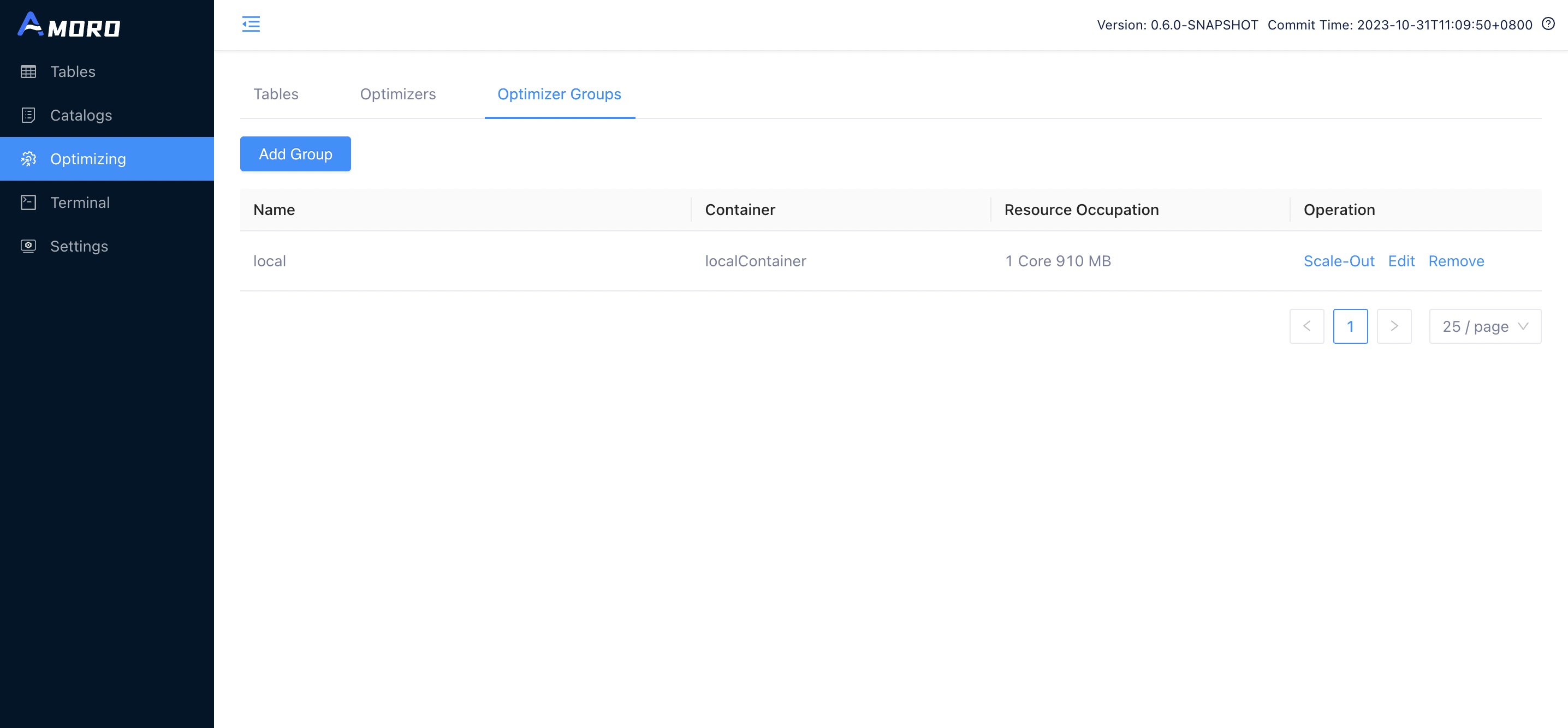
Add optimizer group
You can add an optimizer group on the Amoro dashboard by following these steps:
1.Click the “Add Group” button in the top left corner of the Optimizer Groups page.
2.Configure the newly added Optimizer group.
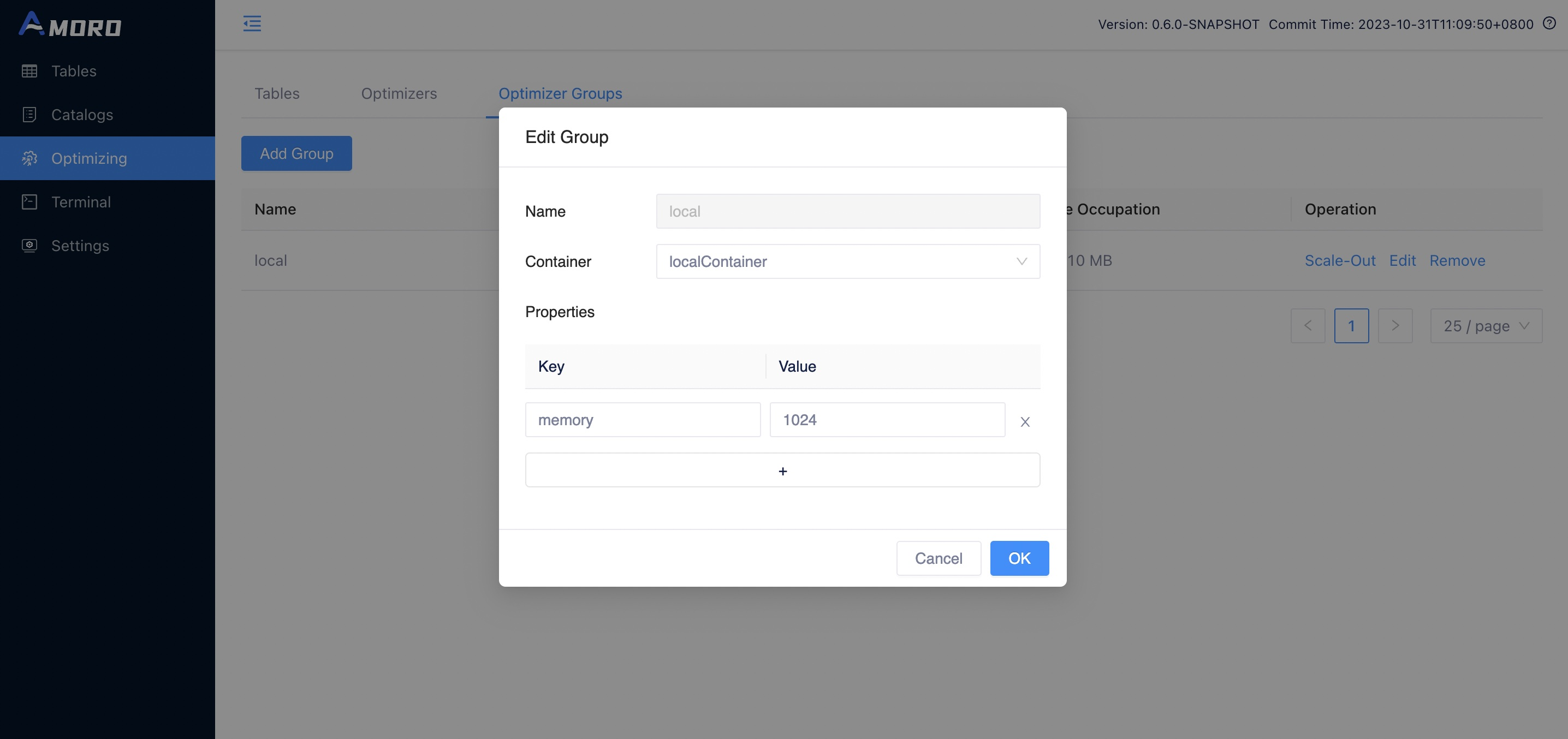
The following configuration needs to be filled in:
- name: the name of the optimizer group, which can be seen in the list of optimizer groups on the front-end page.
- container: the name of a container configured in containers.
- properties: the default configuration under this group, is used as a configuration parameter for tasks when the optimize page is scaled out.Supports native parameters for
flink on yarn, and users can set parameters using theflink-conf.<property>=<value>or useflink-conf.yamlto configure parameters.
The optimizer group supports the following properties:
| Property | Container type | Required | Default | Description |
|---|---|---|---|---|
| scheduling-policy | All | No | quota | The scheduler group scheduling policy, the default value is quota, it will be scheduled according to the quota resources configured for each table, the larger the table quota is, the more optimizer resources it can take. There is also a configuration balanced that will balance the scheduling of each table, the longer the table has not been optimized, the higher the scheduling priority will be. |
| memory | Local | Yes | N/A | The memory size of the local optimizer Java process. |
| ams-optimizing-uri | All | No | thrift://{ams.server-expose-host}:{ams.thrift-server.optimizing-service.binding-port} | Table optimizing service endpoint. This is used when the default service endpoint is not visitable. |
| flink-conf.<key> | Flink | No | N/A | Any flink config options could be overwritten, priority is optimizing-group > optimizing-container > flink-conf.yaml. |
To better utilize the resources of Flink Optimizer, it is recommended to add the following configuration to the Flink Optimizer Group:
- Set
flink-conf.taskmanager.memory.managed.sizeto32mbas Flink optimizer does not have any computation logic, it does not need to occupy managed memory. - Set
flink-conf.taskmanager.memory.netwrok.maxto32mbas there is no need for communication between operators in Flink Optimizer. - Set
flink-conf.taskmanager.memory.netwrok.ninto32mbas there is no need for communication between operators in Flink Optimizer.
Edit optimizer group
You can click the edit button on the Optimizer Groups page to modify the configuration of the Optimizer group.
Remove optimizer group
You can click the remove button on the Optimizer Groups page to delete the optimizer group, but only if the group is
not referenced by any catalog or table and no optimizer belonging to this group is running.
Optimizer Scale-out and Release
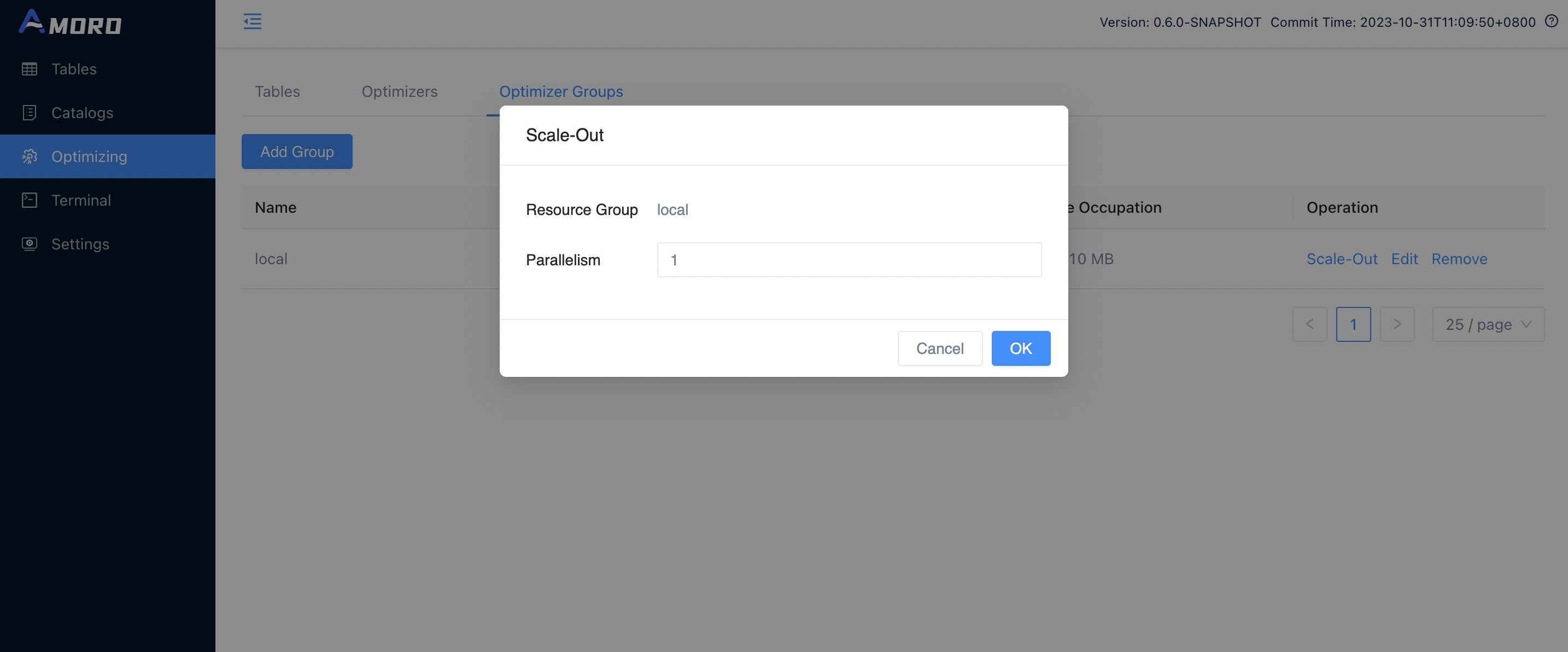
Scale out optimizer
You can click the Scale-Out button on the Optimizer Groups page to scale out the optimizer for the corresponding optimizer
group, and then click OK to start the optimizer for this optimizer group according to the parallelism configuration.
If the optimizer runs normally, you will see an optimizer with the status RUNNING on the Optimizers page.
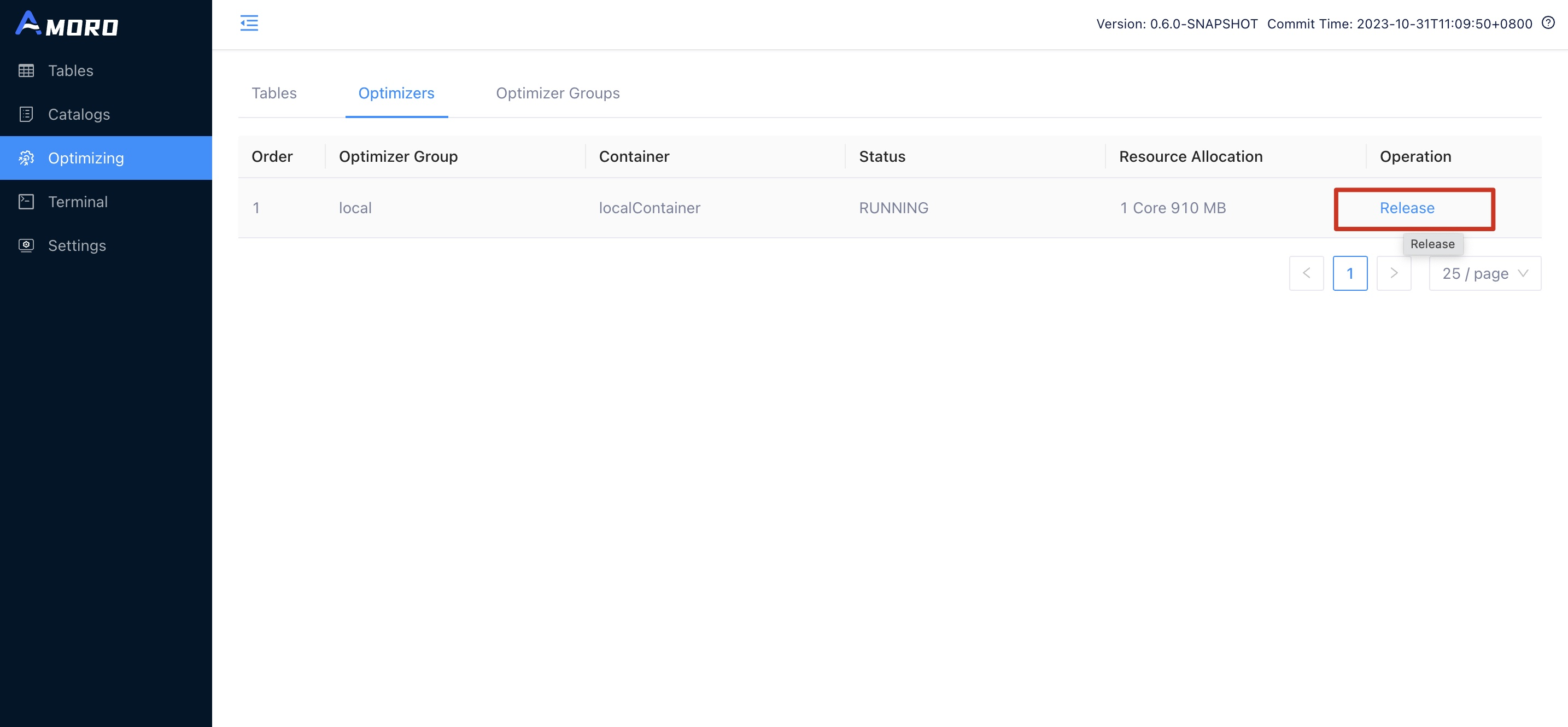
Release optimizer
You can click the Release button on the Optimizer page to release the optimizer.
Deploy external optimizer
You can submit optimizer in your own Flink task development platform or local Flink environment with the following configuration. The main parameters include:
./bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.memory.managed.size=32mb \
-Dtaskmanager.memory.network.max=32mb \
-Dtaskmanager.memory.network.min=32mb \
-c com.netease.arctic.optimizer.flink.FlinkOptimizer \
${AMORO_HOME}/plugin/optimizer/flink/optimizer-job.jar \
-a 127.0.0.1:1261 \
-g flinkGroup \
-p 1 \
-eds \
-dsp /tmp \
-msz 512
The description of the relevant parameters is shown in the following table:
| Property | Required | Description |
|---|---|---|
| -a | Yes | The address of the AMS thrift service, for example: thrift://127.0.0.1:1261, can be obtained from the config.yaml configuration. |
| -g | Yes | Group name created in advance under external container. |
| -p | Yes | Optimizer parallelism usage. |
| -hb | No | Heart beat interval with ams, should be smaller than configuration ams.optimizer.heart-beat-timeout in AMS configuration conf/config.yaml which is 60000 milliseconds by default, default 10000(ms). |
| -eds | No | Whether extend storage to disk, default false. |
| -dsp | No | Defines the directory where the storage files are saved, the default temporary-file directory is specified by the system property java.io.tmpdir. On UNIX systems the default value of this property is typically “/tmp” or “/var/tmp”. |
| -msz | No | Memory storage size limit when extending disk storage(MB), default 512(MB). |